







Superintelligenz: Kontrolle vs Machtverlust
Versuche zur Kontrolle von Superintelligenz
„Superintelligenz” ist das Damoklesschwert der AI. Superintelligenz wäre dem besten menschlichen Hirn in kreativen, sozialen als auch in Problemlösungs-Kompetenzen überlegen.
Was für die einen die Lösung der größten Menschheitsprobleme bringen könnte, bedeutet für andere eine Machtübernahme durch AI.
Die Wissenschaft ist sich uneinig darüber, ob und wann AI das Level der Superintelligenz erreichen könnte, wobei OpenAI, die Firma hinter ChatGPT, in den nächsten 10 Jahren damit rechnet.
Egal ob herannahende Dystopie oder unrealistische Zukunftsvision – es ist unbestritten, dass AI immer ausgefeilter wird und es wird bereits geforscht, wie man eine superintelligente AI unter Kontrolle behalten kann.
Ein Grundproblem bei der Ausrichtung zukünftiger superintelligenter AI-Systeme ist, dass die Menschheit aktuell AI-Systeme überwacht, die „dümmer“ sind als wir, in der Zukunft aber vielleicht eine AI überwachen muss, die viel klüger ist, als wir selbst.
OpenAI hatte dafür das sogenannte Superalignment-Team gegründet, um innerhalb von vier Jahren wissenschaftliche und technische Durchbrüche zu erzielen, um superintelligente AI-Systeme steuern und kontrollieren zu können. OpenAI wollte dafür 20% seiner Rechenleistung zur Verfügung stellen.
Die Problemstellung, dass Menschen AI-Systeme überwachen müssen, die viel schlauer sind als sie selbst, kann man heute nicht direkt testen, aber OpenAI versuchte diese Situation zu simulieren, und untersuchte, ob schwächere AI-Systeme stärkere AI-Systeme beaufsichtigen und leiten können.
OpenAI schilderte, dass man erwarten würde, dass ein starkes Modell nicht besser abschneiden kann, als der schwache Supervisor, der es trainiert – es würde lernen, alle Fehler des schwachen Supervisors zu imitieren. Andererseits hätten starke vortrainierte Modelle hervorragende Grundfähigkeiten – man müsse ihnen keine neuen Aufgaben von Grund auf beibringen, man könne umfangreiches bestehendes Wissen abrufen.
Die entscheidende Frage ist dann: Wird das starke Modell gemäß der zugrunde liegenden Absicht des schwachen Supervisors handeln – indem es seine vollen Fähigkeiten nutzt, um auch schwierige Probleme zu lösen, bei denen der schwache Supervisor nur unvollständige oder fehlerhafte Trainingsdaten liefern kann?
OpenAI nutze ein GPT-2 Modell als schwacher Supervisor für die Feinabstimmung eines stärkeren GPT-4 Modells und teste verschiedene Ansätze (inklusive, dass das stärkere Modell widersprechen kann), um die Fähigkeit von GPT-4 zu erzielen.
Im Ergebnis kam das OpenAI-Team nahe an die GPT-3.5-Leistung, wobei es auch auf schwierige Probleme anwendbar war, bei denen GPT-2 scheiterte.
Siehe Diagramm von OpenAI:
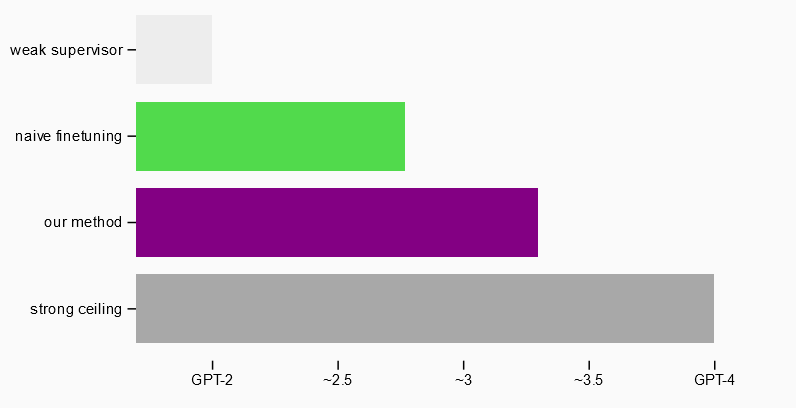
OpenAI schließt daraus, dass es machbar sei, die Ergebnisse einer Interaktion von Schwach zu Stark zu verbessern, und dass dieser Ansatz ein Weg wäre, um messbare Fortschritte bei dem Thema zu machen.
In OpenAIs Ankündigung des Superalignment Teams wurden die prominenten AI-Experten und OpenAI-Mitgründer Ilya Sutskever und Jan Leike als Leiter genannt. Beide verließen 2024 das Unternehmen, Insider berichteten über eine Vertrauenserosion, da der OpenAI CEO scheinbar möglichst schnell mächtige AI-Systeme entwickeln will, anstatt auf Sicherheitsaspekte zu achten. Sutskever gründete eine Firma mit dem Ziel sichere Superintelligenz zu entwickeln und Jan Leike wechselte zum OpenAI-Konkurrenten Anthropic. Mittlerweile wurde OpenAIs Superalignment-Team aufgelöst.
Bis Superintelligenz zur Realität wird, besteht aktuell eher das Risiko, dass AI von Menschen zu Manipulationszwecken genutzt wird: kürzlich wurden mehrere OpenAI-Zugänge der iranischen Geheimdienstgruppe “Storm-2035” gesperrt. Sie erzeugten mit Chat-GPT manipulative Socialmedia Inhalte, um die US-Präsidentschaftswahl zu beeinflussen.